Front-end applications are constantly increasing in complexity. It is not surprising that managing data efficiently in front-end applications is becoming a fundamental requirement.
Front-end frameworks like Angular have multiple external state management solutions such as NgRx, NGXS, and Akita. NgRx is arguably the most widely used with Angular, with a robust set of features. With the right approach, NgRx can help optimize the developer workflow of your team and set up your application for success.
Drawing from their years of experience in the industry, Christian Ludemann and Tomas Trajan discuss industry best practices to follow when working with NgRx.
NgRx schematics
The Angular CLI contains schematics to automate generating boilerplate code for your components and services. NgRx schematics is NgRx’s set of commands to generate code for NgRx-related functionality.
NgRx schematics can generate reducers, actions, selectors, and even entire state features. Furthermore, NgRx schematics also automates integrating the store to its closest module or the module you specify in the command. In short, NgRx schematics automates all the boilerplate requirements and lets you focus on your application.
The automation provided by NgRx schematics has the added benefit of creating standardization and repeated patterns across your applications. Standardization is especially useful when working in larger environments with multiple projects and teams. Having each team and project follow the same structure makes it easy to refactor and for your team to switch between projects without re-learning how each project manages its state.
Developers often complain about the amount of boilerplate required when working with NgRx. Schematics don’t remove this concern. However, it does the heavy lifting for you so you don’t have to go through the pain of writing the boilerplate yourself. You can skip all that and go straight to writing the code you need.
Similar to Angular schematics, you have the option to create your own custom schematics for NgRx specific to your project’s requirements. Tomas, however, recommends using the default schematics unless absolutely necessary. The official NgRx schematics are constantly updated along with the NgRx package, keeping it up to date with the latest best practices. NgRx also provides migration scripts to help update your application to the latest versions. An application that follows the structure recommended by the official schematics makes migration a smoother process with minimal adjustments required.
Recognize and leverage NgRx 80/20 rule
Angular is known for its robust engineering and heavy use of RxJS streams. Both powerful and complex, RxJS has a steep learning curve and takes a while to master. NgRx is similar in a lot of ways. Tomas explains how you can use the 80/20 rule to learn NgRx.
NgRx can be divided into the following five concepts:
– **Store** – where everything is stored
– **Selectors** – retrieve the state or state slice
– **Actions** – notify NgRx an event has happened
– **Reducers** – perform updates on the state in the store
– **Effects** – perform any side effects
Tomas further divides the list into two sections:
– contains only pure typescript implementations
– contains Angular-specific implementation.
Pure functions make up 80% of NgRx. They are all pure typescript with plain data structures and don’t contain anything Angular-specific. This characteristic of the majority of NgRx makes it significantly easier to learn and test.
NgRx encourages centralizing your application’s logic within NgRx, leaving your components with minimal logic. Since 80% of NgRx are pure functions, most of your application logic will be less dependent on Angular features. As previously established, pure functions are easier to test. Moving the logic into pure functions means that your application will be easier to test and could lead to higher test coverage.
For the remaining 20%, NgRx’s effects are the only part that uses Angular functionalities (DI injection). Effects are similar to Angular services, with some NgRx necessities. Every effect starts with a stream (any observable – stream of actions, scroll events, etc.). NgRx offers a nice abstraction when dealing with the said stream by handling the subscription process behind the scenes. This abstraction allows you to work with the streams and perform RxJS operations without worrying about manually subscribing and unsubscribing. In addition, the structure of effects allows you to chunk them into small pieces, making them easy to follow and maintain.
When in doubt, move your logic one level up
As a general rule, Tomas recommends implementing every feature as a lazy-loaded feature. Outside of NgRx, lazy-loaded features provide your application with the following benefits:
– Faster startup time
– Faster rebuild time
– Smaller bundle size
Besides the improved experience for both end-users and developers, lazy-loaded features also enforce the following rules which prevent developers from misusing each feature.
– Lazy features cannot import from each other – guarantees isolation
– A change in one feature cannot affect or break a different feature
How you set up your features impacts how your NgRx code will be structured. NgRx state can be divided into two:
– **Eager state** – state required from the beginning and/or in multiple features (example: user state, authentication state)
– **Feature state** – state required by the feature
As your application grows and requirement changes, a state in feature A may be now required in feature B. There are two approaches we can take to modify our application and still adhere to the rules mentioned above.
Move the required state (feature A’s state) one level up (example: from feature A to eager)
If only a part of the state is required, split the reused part and move the required state slice (a subsection of feature A’s state) one level up (example: from feature A to part of the eager state)
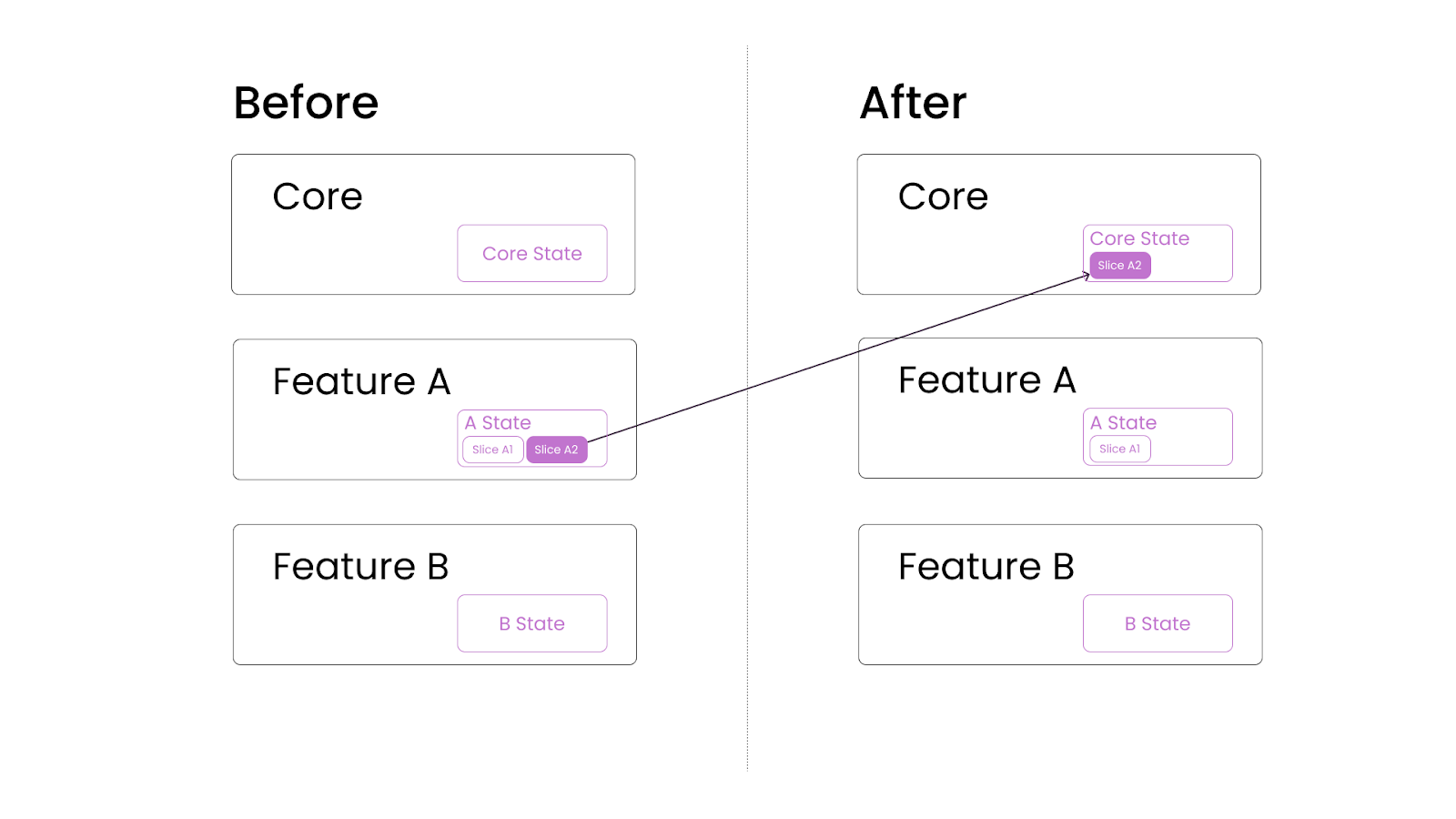
Moving Slice A2 from Feature A to Core
The same approach can be applied to nested features as well. The example below shows how feature A1’s state can be moved when it is required by feature A2.
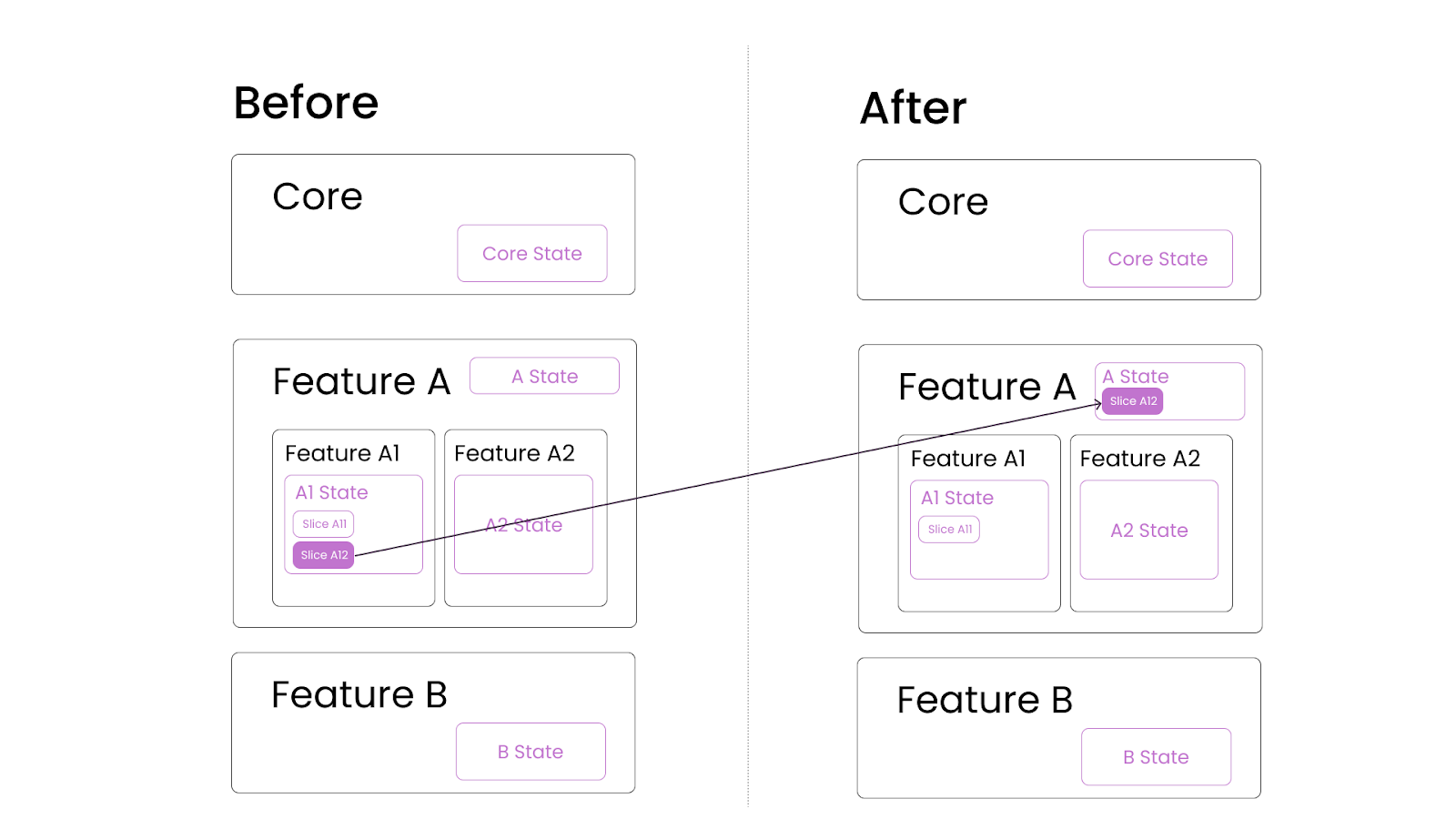
Moving of Slice A12 from Feature A1 to Feature A
A benefit of maintaining the above architecture is the ease of refactoring in the long run. Christian adds that following this rule, moving (not duplicating) state as per your requirements avoids introducing bugs related to inconsistent states between features.
For those of you using Nx, Nx’s domain-driven architecture brings this to a new level with additional rules to prevent cross-feature imports. Nx helps validate your architecture by controlling your application’s dependency flow. Nx automates the checks discussed in this section, making sure that your application doesn’t break any of the rules stated above. This is especially useful when working on a complex project with a large team.
Create perfect view selectors for container components
Container components use NgRx’s selectors to access state slices. They then listen to changes in the state slice using one of two approaches below:
– `subscribe()` function on the observable
– `async` pipe to subscribe from the template
This approach works great for single selectors. However, it is common to require data from different states or format the data specific to how the component uses them. Combining multiple streams and creating a derived state in the component pollutes the component file and makes it difficult to test.
Tomas recommends splitting the code that handles combining multiple streams and creating derived states into a separate file (`*.component.selector.ts`).
Moving the logic out of the component decouples the component template from NgRx and leaves your components slim with minimal business logic. In addition, the separate file handling the data manipulation doesn’t use any Angular-specific features, making it easier to test.
Sometimes it’s not possible to strip out all the logic from a component. Components containing forms typically require logic to process the form. However, the fewer the logic in the component, the better.
The example below shows a `dashboard.component.selector.ts` file with the “perfect view selectors” that combines two selectors into one. The selector can then be subscribed in the `DashboardComponent`, avoiding having to subscribe to multiple selectors in the component.
Action as events
In a reactive data flow, everything is event-driven. An event triggers a set of codes to be executed. Similarly, NgRx actions are more similar to raising an event rather than issuing a command.
Tomas recommends always naming your actions as events as these will prove advantageous in both scaling and debugging your application.
Using actions as commands can make things confusing as you wouldn’t know what triggered the action, especially if multiple flows can trigger the same action. For example, an action called “Add Order” might be reused and called from the product list page or the product details page. Because it’s reusing the same action from different parts of the application, some event details are lost.
Events, on the other hand, will give you a more verbose description of how the action happened and where it was triggered. The “Add Order” action can be re-written as the following events:
– “[Product List] User Added Item To Basket” – when a user adds the product via the product list page
– “[Product Details] User Added Item To Basket” – when a user adds the product via the product details page
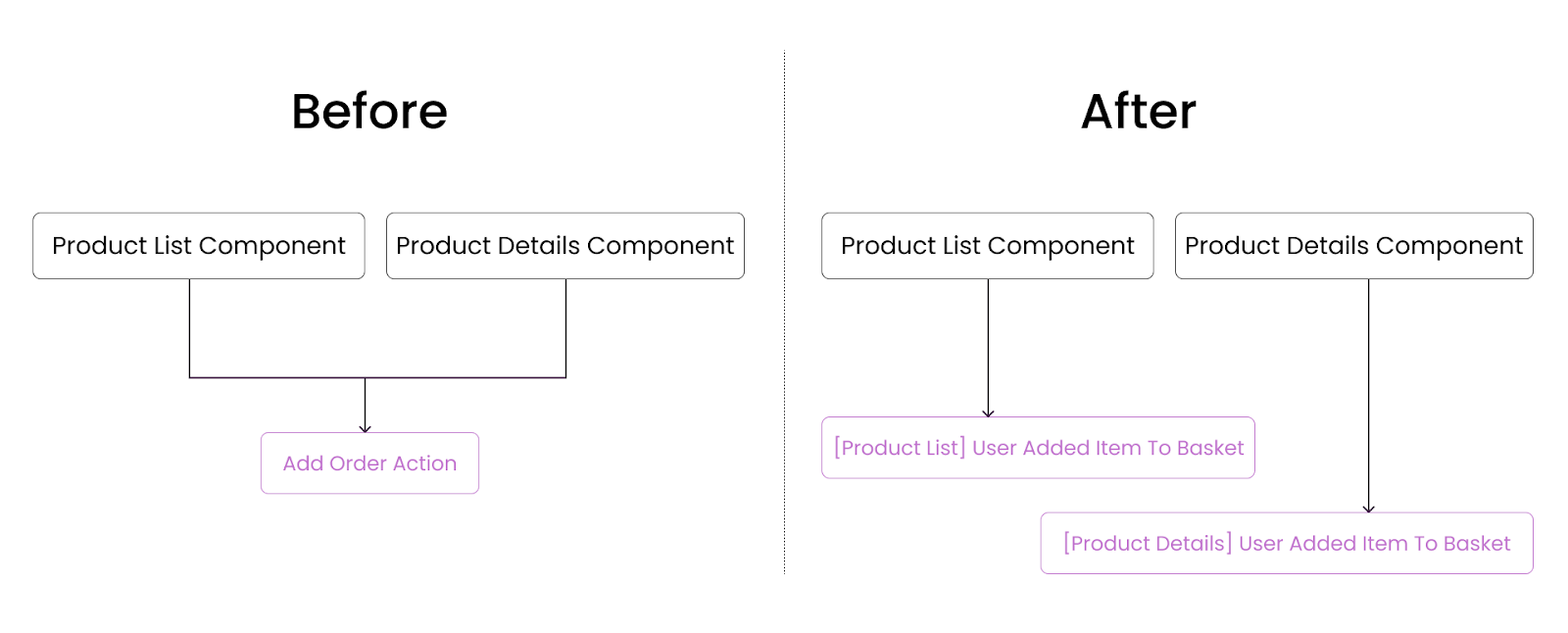
Comparison of using command actions vs event actions
From a debugging perspective, you can get a lot more information just by looking at the list of actions dispatched from your application. You will most likely be able to understand what is going on without having to go through the code.
Reducers and effects can listen to multiple events. This means that you can create as many events as you need that call the same reducer or effects. The paradigm shift from commands to events and structuring your NgRx store in this manner better decouple the view layer from the state layer.
Get comfortable using Redux devtools
Redux devtools is a browser extension that you can install to help with debugging NgRx-related functionalities.
Redux devtools has a robust set of features including:
- View your application’s action logs
- View the diff in the state between before and after an action was triggered
- View a snapshot of the state at a point in time
- Travel through time and step through the list of actions
Because of its robustness, a huge state can cause performance issues. This is due to Redux devtools saving the history of your state to generate useful debugging info. Luckily, NgRx provides state and action sanitizers that can be used to clean up your data to reduce the amount of state (for example, multiple arrays with thousands of items) to improve the performance of the devtool. Although you end up with less information to work with, it is still better than not having any information at all.
Effects are for orchestration only
As the application grows, it’s common to end up with business logic written as part of the effects flow. However, this isn’t what effects were designed to do. Effects are for orchestration. Business logic should be moved to services, and they should only be called in the effects.

Flow of accessing services from effects
Splitting the business logic from effects makes your application cleaner and easier to test. Testing the business logic can be done in the services themselves. Effects, on the other hand, can be tested using by mocking the services. Orchestration-heavy effects can also be tested using marbles, to validate that the sequence of events occurs correctly.
Any RxJs stream can trigger an Effect
NgRx effects triggers aren’t limited to NgRx actions. Any RxJs stream can trigger an Effect. Below are a few common use cases of actionless effects:
user interaction (example: scroll or click events)
timer-based or periodic processing (example: refreshing auth token)
router events (example: navigation start and navigation end events)
The code snippet below shows an NgRx effect listening to scroll events.
“`typescript
handleScrolledToEnd$ = createEffect(() =>
this.scrollService.scrolledToEnd$.pipe(
map(() => UIActions.ScrolledToBottom())
)
);
“`
Normalizing vs duplication of state
NgRx is designed to be a single store that serves as a single source of truth. However, overlap in state is inevitable. If not careful, this could quickly lead to a lot of manual synchronization code to keep the duplicated states in sync. Manually syncing the state is prone to bugs as it relies on the code being perfect all the time. Forgetting to update synchronization logic is often the primary cause of inconsistent bugs in your application with duplicated state.
Keeping everything in a single source of truth reduces the chance of introducing these types of bugs. Using NgRx doesn’t imply that you won’t run into issues with state duplication. It is on us, as the developers, to use NgRx correctly and refactor the code to avoid state duplication. Although not always possible, reducing duplication should always be the goal when working with NgRx.
A common problem with NgRx and other state management libraries is saving derived state in your state object. The derived state is often updated via the reducer as a result of a change in another part of the state. This can cause the derived state to get out of sync if any of the reducers forgets to also update the derived state. That is the reason why NgRx recommends always accessing the derived state via selectors instead of saving it in the state object.
When should you use NgRx?
With multiple state management libraries such as NgRx, NGXS, and Akita, it can be difficult to decide which one to use and whether to even use a state management library for your project.
Tomas recommends basing your decision on two questions:
– How big is the state?
– How isolated the state is (how interconnected each feature is and how much of the state is reused in different parts of the application)?
A relatively large application with numerous features that are independent of one another might not require a robust state management solution like NgRx. Because the state is completely isolated, a lightweight solution might be more suitable.
On the other hand, a small application with interconnected components that require complex orchestration might benefit from using an external state management library like NgRx.
Derived state and optimizing performance
Performance problems can arise once you start working with large data in your state. Sometimes, side-stepping some of the recommended best practices might be the only option for your particular use case.
A selector that computes derived state dynamically might start slowing down as the complexity of the computation increases or the size of the input increases. This is an especially common problem in growing applications.
Christian suggests saving a minimal derived state in the store that acts as a cache to reduce the amount of computation done in the selector and improve the performance of your application.
An alternative solution suggested by Tomas is to optimize your selector by using an impure selector that accesses data outside of the state. The data can act as a cache and short-circuit the logic in your selector to prevent performing unnecessary computation.
What state should be stored in the store
Every application’s requirements are different and there is no one size fits all solution.
Christian suggests saving any data that is used in multiple parts of your application in your root store. The root store acts as a global state providing easy access for any part of your application to access said state.
Tomas further adds that he divides his state into two parts:
– Entity state slice – API-related data
– View state slice – View related data (example: search, filter, and sort)
A rule of thumb that Tomas follows is to store any state that is deep-linkable (can be navigated directly) should be put in the store. This centralizes all the logic (both entity and view) to be handled in a single place.
Forms are a special type of component that can be used with NgRx in several different ways. Tomas recommends using the state from NgRx as the initial state of the form and only synchronizing it back to NgRx after the user has saved or submitted the form instead of on every form field update.
Facades or not
There are both pros and cons to using facades. Perfect view selectors are a form of facade that abstracts your selectors from your component. A light facade that acts as a proxy between your component and NgRx is perfectly fine as long as you don’t start adding business logic or any NgRx features in the facades.
Christian recommends using facades as a bridging layer if you are working with multiple state management solutions from your view layer. The facade can act as an aggregator that hides the state management from your view layer. A facade can also be beneficial if you are still early in development and haven’t decided on a state management library yet. You can then update your state management in the facade without modifying your component.
When using industry-standard tools like NgRx exclusively in your application, a facade might not be needed as you can think of the tool as the right level of abstraction – NgRx as the facade to the underlying state management logic.
Conclusion
These are best practices from the combined experiences of Tomas and Christian that you can implement in your projects. All the best practices discussed in this post aren’t set in stone. They are good rules to follow, but there are always exceptions and some that might not work for your specific use cases. Use the recommendations that are applicable for your use case and make your project more scalable and maintainable.
—
Do you want to become an Angular architect? Check out Angular Architect Accelerator.
Connect with Tomas:
– Twitter – @tomastrajan







1 thought on “NgRx Industry Best Practices (with Tomas Trajan)”
All this time she was chasing her not him